
网站蜘蛛爬取页面怎么引导正常?其实这问题说复杂不复杂,说简单也不简单。要是你真心想让搜索引擎蜘蛛顺利地爬取网站的页面,那可得下点功夫,不能只是光想着让蜘蛛不迷路。呃,我们得确保蜘蛛的爬行路径清晰、顺畅,而且最好能有一些小技巧,让它们能更好地理解网站的结构。
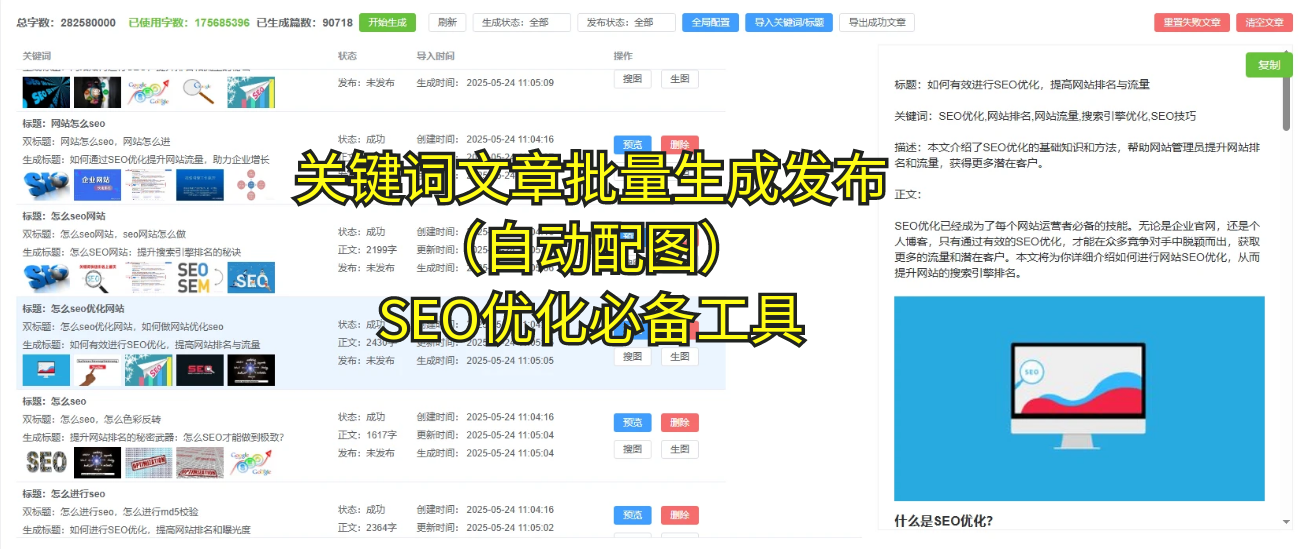
首先啊,必须得有个清晰的网站地图。其实网站地图是蜘蛛“导航”的重要工具,没它,蜘蛛就像是在迷雾中四处乱走,找不到正确的路。这就像你出门没有地图,完全没头绪。网站地图能帮助蜘蛛理解哪些页面是最重要的,哪些可以暂时不爬。嗯,听起来是不是有点深奥?简单来说,就是让搜索引擎更容易识别网站结构。

再者,合理的链接结构非常关键。一般来说,网站的页面层级不要太深,嗯,不然蜘蛛可能需要花费更多的时间来爬取你的页面,而且可能会跳过一些不太重要的内容。所以说,尽量保持页面的层次结构清晰,避免深度超过三层。如果不小心做成了迷宫,蜘蛛可能连入口都找不到。
而且,话说回来,你得保证网站加载速度快。如果网站加载缓慢,不仅用户体验差,蜘蛛也不会太喜欢这样的网站。蜘蛛可不像人类一样能耐心等待几秒钟,它们希望迅速爬取页面。哦,对了,我认为选择一些优秀的SEO工具,比如西瓜AI,能帮助你优化页面速度,确保蜘蛛能够顺利爬取所有重要页面。
有时候,网站中的某些页面内容更新不频繁,或者内容太杂乱,这样的页面可以使用noindex标签。这标签是告诉蜘蛛,“嘿,这个页面不用爬了,暂时不需要索引。”嗯,这就像是把蜘蛛请出门,避免它浪费时间。其实合理利用noindex标签能够帮助蜘蛛集中精力爬取对SEO有用的页面,嗯,是不是很聪明?
当然,站内的链接也得合理安排,确保蜘蛛能顺利地从一个页面跳到另一个页面。我个人感觉,网站的内容结构越清晰,蜘蛛的爬取就越高效。如果页面内容和链接没有良好的逻辑关系,那蜘蛛就像迷了路的旅客,不知道该走哪里。比如,你可以通过导航栏、面包屑等方式来引导蜘蛛,保持内部链接的流畅性,避免断链现象。
说到这里,有没有感觉信息量有点大了?别急,我这里插播一下其他用户的问答。有个小伙伴就问过我:
问:网站的页面是否需要通过robots.txt来限制蜘蛛爬取某些页面? 答:其实这个要根据你的实际需求。如果某些页面确实不希望被爬取,像登录页面、隐私政策等,使用robots.txt来限制蜘蛛访问就可以了。这样可以避免不必要的爬取。
不过,说实话,蜘蛛爬取的规律并不是一成不变的,搜索引擎不断更新算法,蜘蛛的行为也会有所变化。为了应对这种情况,定期检查爬取日志、更新网站结构就显得特别重要。
页面的内容质量同样也不能忽视,嗯,如果页面的内容充实、原创且有价值,蜘蛛自然就更愿意频繁爬取了。如果内容质量太差或者堆砌关键词,蜘蛛反而可能会减少对该页面的关注。所以,还是得确保内容真实且具备一定的深度。
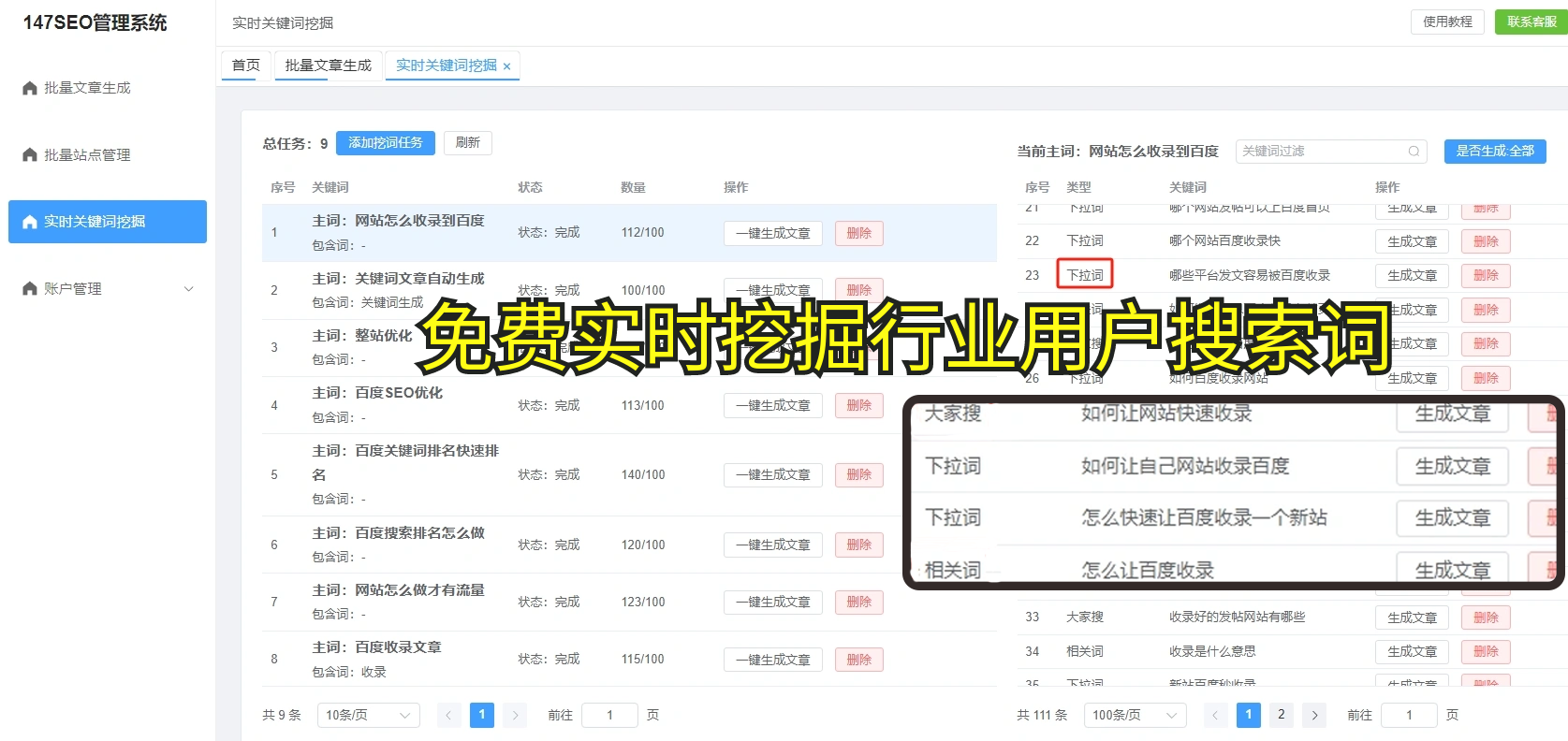
说到内容,很多时候大家也会关注怎么找到一些热门的关键词来提升自己网站的流量,呃,这里也有一些小技巧。例如,使用一些实时关键词功能,像好资源SEO提供的相关工具,能帮助你立刻捕捉到正在火热搜索的关键词,进而让你的网站内容更加贴近用户需求。
回到我们今天的主题,蜘蛛的正常爬取不仅依赖于技术层面的优化,也离不开内容的质量、页面的结构等多个因素。把这些都考虑到位了,蜘蛛的爬取就会更顺畅,网站的排名也会因此逐步提升。
希望通过这篇文章,大家能更清晰地理解如何引导蜘蛛正常爬取页面,确保自己的SEO优化工作不白做。关于SEO还有什么其他问题需要讨论的吗?

